
All About Mappings
(Image: Belgian artillery officer in his office controlling his Batteries by map and ‘phone.
© IWM (Q 2950) )
At the heart of our API lies our mappings infrastructure. It is two-fold: Queries are issued to our API in Solr-like syntax, which can be passed straight through to Solr sources including the ones I set up in my last post. For other source types, we must map our Solr query into a query suitable for a non-Solr source. This is the federated approach discussed in my aggregation vs federation post.
The other side of the mappings infrastructure is that each provider returns responses with their own unique metadata structure, so we must decide on a common metadata format for results and convert everything into it before our API serves them.
The bulk of the work in the mappings infrastructure surrounds these result mappings, and so I want to go into them in more detail in this article. However, there is also an appendix briefly discussing mappings made upon queries before they are issued to providers, and because the result mappings files were a piece of work in themselves and have become a deliverable of our project, there is an appendix discussing the more technical approach behind the mappings infrastructure, as well as offering links to the mappings we have produced.
Result Mappings
We started off with a very basic core of mappings (title, media location, description) just to get our initial application off the ground (see legacy mappings below), and then once we had more of an idea as to the range of metadata being returned, we were able to expand this basic set outwards on a provider-by-provider basis.
In the meantime, we adopted the standard of leaving unmapped metadata fields in our output, prefixed with their provider’s abbreviated name (e.g. iwm.internal_id). Even after we had done a more rigorous mapping exercise, for various data fields this was still the only approach which really made sense, and so there are still several fields like this in our API output. This behaviour remains the default for any metadata field for which we have not specified a mapping, and so I have added an unmapped="true" attribute to distinguish fields for which this behaviour is intentional, from fields for which we have not yet seen in our sample outputs and therefore not yet had the chance to allocate to a more formal metadata scheme (and there are a few of these still cropping up even now)
Some providers (most notably Culture Grid) had already run through a similar exercise and were already returning scheme-rich metadata fields such as dc.title and dcterms.relation, and from looking at their outputs we realised that the extended Dublin Core covered almost all of the metadata fields we were seeing which fitted into our ‘common set of useful fields to return’ approach. The main exception was a practice we discovered in IWM and National Maritime Museum‘s metadata, which was to identify the resolution and/or file size of their digital content to deal with cases where they were offering several sizes for consumption. For this practice we adopted JISCDiscovery. as a metadata prefix.
Providers also fell neatly into two categories — those who were returning absolute URIs to their content in their output, and those who assumed knowledge of a base URI path from their API documentation, and so only supplied the relative paths to the media. The latter is good evidence of people eating their own dog food! Originally, we honoured both cases, but later we decided that our API being external to our providers meant there was no sense in offering relative paths from our API, and so switched to returning absolute paths throughout.
At first, we purely envisaged the mappings exercise as finding the new field name for every piece of metadata we ran into from all the providers. After a while, however, it became apparent that in some cases we would have to make alterations to the data themselves in support of our common metadata set becoming meaningful. For this purpose, I added a post-processor routine. However, the variations in data across providers means that there is a lot more work to be done in this area (in particular see comments regarding locations and timelines in my article on features, trends and further work)
Take a look through the appendices below for more technical detail on how mappings are achieved, and in my final post I will sum up everything we have achieved and round off the technical aspects of our project!
Appendix: Legacy Mappings
Legacy mappings are still returned in the API for compatibility with some of the interfaces we commissioned from external companies (more about this in my next post). I have extended Solr’s result format to add legacy_mapping_instead_use=, followed by the new suggested term, for these mappings so that they can be identified by consumers of our API and removed at a later date.
Appendix: Query Mappings
My API Syntax post details the final set of API options for which we were able to build in some sort of response.
The main option which required consideration for mapping between sources was q=, which is Solr’s syntax for the search terms — for other API types the parameter name and even content may need altering. For example, Solr search terms can be separated with commas, whereas other providers use + or in one case don’t actually support multiple terms. The most complex mapping comes with OCLC Contentdm, which has a more complicated string of parameters into which the Solr-style query string must be inserted.
Looking inside some of our mappings files you will find a <query> section which details some more of the adjustments which are required.
Appendix: Technical Approach for Mapping Results
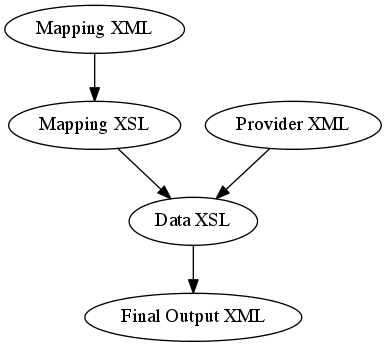
Every single provider we worked with had an option, if not a default, of returning metadata in XML format. This made a choice of XSL for the data transformation a straightforward one. One Data XSL transform per provider, however, seemed like overkill and a lot of repetition, so I set out to devise a simple XML structure describing the mappings for each provider, with the idea being that a Mapping XSL transform on this Mapping XML would yield the main Data XSL transform for use on the Provider Data. I was impressed by how easy XSL makes this kind of ‘programs which write programs’ approach!
At first I drew up one Mapping XSL file per API type, but from the amount of repetition I was starting to use it became obvious quite early on that the procedural ideas behind the transform were the same for each provider’s XML structure, with just a few minor processing modifications depending on the output type. Eventually, I came up with one universal Mapping XSL covering the five different API types (Solr, Europeana Opensearch, Victoria and Albert Museum, Oxford Continuations and Beginnings RSS, Manufacturing Pasts Contentdm).
You can download the raw Mappings XML for each of our providers (although Europeana mappings have been sanitised to obscure our API key and you will need to use your own). There is a separate <results> section within the files for processing the results.
Related Posts

Final features, Trends and Future Work →

Helping Institutions Towards APIs →

Release of WW1 Discovery Interfaces →
